DataX 引擎
一、DataX简介
DataX是阿里巴巴发布的开源项目(详情请访问DataX的Github主页),是一个高效的离线数据同步工具,常用于异构数据源之间的数据同步。
DataX采用的是Framework + plugin架构,数据源读取和写入分别对应Reader与Writer插件,每一种数据源会有对应的Reader或者Writer,DataX默认地提供了丰富的Reader与Writer支持,用于适配多种主流数据源。Framework用于连接Reader和Writer,并负责同步任务中的数据处理、扭转等核心过程。
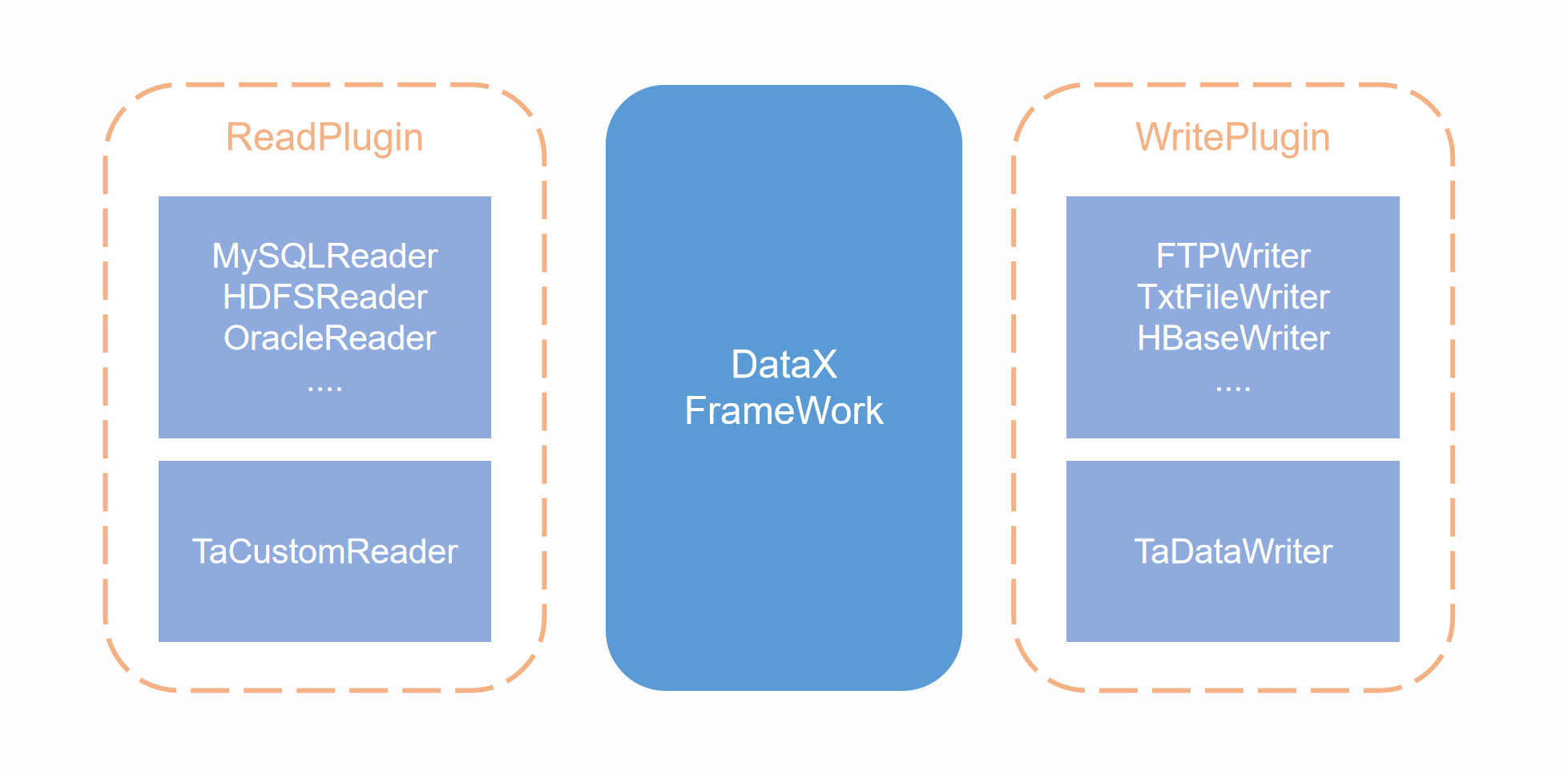
DataX的数据同步任务,主要通过一个配置文件进行控制,其中最主要的配置是Reader与Writer的配置,这两者分别代表如何从数据源抽取数据,以及如何将抽取的数据写入数据源。通过在配置文件中使用对应数据源的Reader与Writer,即可完成异构数据源的同步。
在ta-tool中,我们集成了DataX引擎,并且编写了TA集群的插件(即TA集群的Reader与Writer),借由TA集群插件,可以将TA集群的作为DataX的数据源。
通过ta-tool中的DataX引擎,您可以完成以下数据同步:
- 将其他数据库中的数据,导入到TA集群,需要使用DataX的已有Reader插件与TA Writer
- 将TA集群的数据,导出到其他数据库中,需要使用TA Reader与DataX的已有Writer插件
二、DataX引擎的使用方式
如果需要使用ta-tool中的DataX引擎进行多数据源同步任务,那么首先需要在TA集群中编写DataX任务的Config文件,其次是执行二次开发组件中的DataX命令,读取Config文件执行数据同步任务。
2.1 配置文件样例
DataX的任务Config文件需要是一个json文件,json配置的模板如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
整个配置文件是一个JSON,最外层"job"元素,其中包含两个元素,分别为"content"和"setting","content"内的元素中包含reader和writer的信息,可以在本文后续部分查看TA集群的Reader和Writer。"setting"中的"speed"内的"channel"是同时执行的任务数。
配置文件中主要需要配置的部分为"content"中的"reader"和"writer"元素,分别配置读取数据的Reader插件以及写入数据的Writer插件。DataX预置的Reader和Writer插件的配置方法,请访问DataX的Support Data Channels部分。
2.2 执行DataX命令
完成配置文件的编写后,可以执行以下命令读取配置文件,并开始数据同步任务。
ta_tool datax_engine -conf <configPath> [--date <date>]
传入的参数为配置文件所在路径。
三、TA集群的DataX插件说明
3.1 向TA集群写入数据——TaDataWriter 说明
3.1.1 介绍
TaDataWriter提供了DataX向Ta集群传输数据的功能,数据将会发送到TA的receiver。
3.1.2 功能与限制
TaDataWriter实现了从DataX协议转为Ta集群内部数据功能,TaDataWriter如下几个方面约定:
- 支持且仅支持写入Ta集群。
- 支持数据压缩,现有压缩格式为gzip、lzo、lz4、snappy。
- 支持多线程传输。
3.1.3 功能说明
3.1.3.1 配置样例
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": 123123,
"type": "long"
},
{
"value": "123123",
"type": "string"
},
{
"value": "buy",
"type": "string"
},
{
"value": "2019‐08‐08 08:08:08",
"type": "date"
},
{
"value": "2019‐08‐08 08:08:08",
"type": "date"
},
{
"value": "2222",
"type": "string"
},
{
"value": "2019‐08‐08 08:08:08",
"type": "date"
},
{
"value": "test",
"type": "bytes"
},
{
"value": true,
"type": "bool"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "ta‐data‐writer",
"parameter": {
"thread": 3,
"type": "event",
"connType":"http",
"appid": "34c703a885014208a737911748a7b51c",
"column": [
{
"index":"0",
"colTargetName":"testNumber",
"type":"number"
},
{
"index": "1",
"colTargetName": "#distinct_id"
},
{
"index": "2",
"colTargetName": "#event_name"
},
{
"index": "3",
"colTargetName": "#time",
"type": "date",
"dateFormat":"yyyy‐MM‐dd HH:mm:ss.SSS"
},
{
"index": "4",
"colTargetName": "#event_time",
"type": "string"
},
{
"index": "5",
"colTargetName": "#account_id",
"type": "string"
},
{
"index": "6",
"colTargetName": "timetest",
"type": "date",
"dateFormat":"yyyy‐MM‐dd HH:mm:ss.SSS"
},
{
"index": "6",
"colTargetName": "timetest2",
"type": "date",
"dateFormat":"yyyy‐MM‐dd HH:mm:ss"
},
{
"index": "7",
"colTargetName": "os_1",
"type": "string"
},
{
"index": "7",
"colTargetName": "os_2",
"type": "string"
},
{
"index": "8",
"colTargetName": "booleantest",
"type": "boolean"
},
{
"colTargetName": "add_clo",
"value": "123123",
"type": "string"
}
]
}
}
}
]
}
}
3.1.3.2 参数说明
- thread
- 描述:线程数。
- 必选:否
- 默认值:1
- type
- 描述:写入的数据类型user_set、track。
- 必选:是
- 默认值:无
- compress
- 描述:文本压缩类型,默认不填写意味着没有压缩。支持压缩类型为zip、lzo、lzop、tgz、 bzip2。
- 必选:否
- 默认值:无压缩
- appid
- 描述:对应项目的appid。
- 必选:是
- 默认值:无
- connType
- 描述:集群内部的接受数据方式,走receiver还是直接发送到kafka。
- 必选:是
- 默认值:kafka
column
描述:读取字段列表,
type指定数据的类型,index指定当前列来对应reader的第几列(以0 开始),value指定当前类型为常量,不从reader读取数据,而是根据value值自动生成对应 的列。 用户可以指定Column字段信息,配置如下:[{ "type": "Number", "colTargetName":"test_col", //生成数据对应的列名 "index": 0 //从reader到datax传输第一列获取Number字段 }, { "type": "string", "value": "testvalue", "colTargetName":"test_col" //从TaDataWriter内部生成testvalue的字符串字段作为当前字段 }, { "index": 0, "type": "date", "colTargetName": "testdate", "dateFormat":"yyyy‐MM‐dd HH:mm:ss.SSS" }]对于用户指定Column信息,
index/value必须选择其一,type非必选,设置date类型时,可设置dataFormat非必选。- 必选:是
- 默认值:全部按照reader类型读取
3.1.3.3 类型转换
类型是TaDataWriter定义:
| DataX 内部类型 | TaDataWriter 数据类型 |
|---|---|
| Int | Number |
| Long | Number |
| Double | Number |
| String | String |
| Boolean | Boolean |
| Date | Date |
3.2 读取TA集群数据——TaCustomReader 插件
3.2.1 介绍
TaCustomReader插件实现了DataX从Ta读取数据。在底层实现上,TaCustomReader通过JDBC连接远程TA数据库,并执行相应的sql语句将数据从TA库中SELECT出来。
3.2.2 实现原理
简而言之,TaCustomReader通过JDBC连接器连接到远程的TA数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到TA集群,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。
3.2.3 功能说明
3.2.3.1 配置样例
配置一个从Mysql数据库同步抽取数据到本地的作业:
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "ta‐custom‐reader",
"parameter": {
"username": "ta",
"querySql":"select * from v_event_1 where \"#user_id\" = 319"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true,
"encoding": "UTF‐8"
}
}
}
]
}
}
3.2.3.2 参数说明
- server
- 描述:描述的是到对端TA数据库的连接信息,SERVER:PORT 形式。
- 必选:否
- 默认值:同步集群配置
- querySql
- 描述:在有些业务场景下,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项 之后,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用
select a,b from table_a join table_b on table_a.id = table_b.id - 必选:是
- 默认值:无
- 描述:在有些业务场景下,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项 之后,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用
3.2.3.3 类型转换
目前TaCustomReader支持大部分Presto类型,但也存在部分个别类型没有支持的情况,请注意检查 你的类型。
下面列出TA-reader针对TA集群使用的presto类型转换列表:
| DataX 内部类型 | Presto 数据类型 |
|---|---|
| Long | TINYINT, SMALLINT, INTEGER, BIGINT |
| Double | REAL, DOUBLE, DECIMAL |
| String | VARCHAR, CHAR, VARBINARY, JSON |
| Date | DATE, TIME, TIMESTAMP |
| Boolean | BOOLEAN |
请注意:除上述罗列字段类型外,其他类型均不支持